Data transformation is an important aspect of Data Engineering and can be a challenging task depending on the dataset and the transformation requirements. A bug in data transformation can have a severe impact on the final data set generated leading to data issues. In this blog I am going to share my experience of having missing values in Pandas DataFrame, handling these missing values in Pandas and converting the Pandas DataFrame to Spark DataFrame.
To give a quick background, I was writing a data transformation (ETL) job in AWS Glue using PySpark which was to be executed every 15mins. The final data written to snapshot table was expected to have ~1k records per execution in the snapshot table with null values. The flow of the job was as follows:
- The AWS Glue job imports all the required modules from awsglue and pyspark. It also imported awswrangler and pandas
- Query a view and a table (snapshot table) with set operation EXCEPT using awswrangler calling aws athena API to get the incremental records in every execution of the Glue job
- The incremental record set created using AWS Data Wrangler is stored as Pandas DataFrame. The records had some missing values (<NA>) and it was expected
- Convert the Pandas DataFrame to Spark DataFrame
- Perform inner joins between the incremental record sets and 2 other table datasets created using aws glue DynamicFrame to create the final dataset
- Write the final data set to S3 using Spark write operation
Lets get into more details:
Below is the code snippet to get the incremental records based on the view and the snapshot table –

To execute the SQL using AWS Data Wrangler call awswrangler.athena.read_sql_query API

AWS Data Wranglers returns the result as Pandas DataFrame. To convert a Pandas DataFrame to Spark DataFrame use the below code

At this step the AWS Glue job was failing with –
TypeError: field completion_response: Can not merge type <class 'pyspark.sql.types.StructType'> and <class 'pyspark.sql.types.StringType'>
Spending some time on the error, I understood that it could be because of the missing values which pushes Pandas to represent them as mixed types and is failing while converting them to Spark. Spark by default infers the schema based on the Pandas data types to PySpark data types. As missing values/nulls were expected in the dataset, I thought the best to avoid this issue was to provide schema when converting to Spark DataFrame.

Convert Pandas DataFrame to Spark DataFrame with above schema –

Post this change, the AWS Glue job were completing successfully. After few successful executions, I looked into the data in target table and noticed that more than 140K records were being written to the snapshot table in every execution of the job. In every execution with 15mins interval we were expecting no more than ~1K records. So definitely there was some bug in the code. Doing some dive deep, I noticed that the string data type columns which had missing values in the Pandas DataFrame had some weird values in the target table. My expectation was that the data with missing values in the Pandas DataFrame will be written as null in the Spark DataFrame, but it did not seem to be the case.
As an example in the below screenshot, the completion_response column in snapshot table was showing some random string value instead of null. In the Pandas DataFrame the same record had missing value (represented as <NA> ) for completion_response column. Due to this the query executed in Athena with set operation EXPECT was giving wrong results.

Let’s dive a little more deeper with an example of a record in Pandas DataFrame.

As you can see, the completion_response is missing for this record. Looking at the Pandas DataFrame summary using .info() method, the data types of the columns have been correctly identified. The columns containing sting has been identified as string data type and columns containing dates have been identified of datetime64[ ns ] data type.
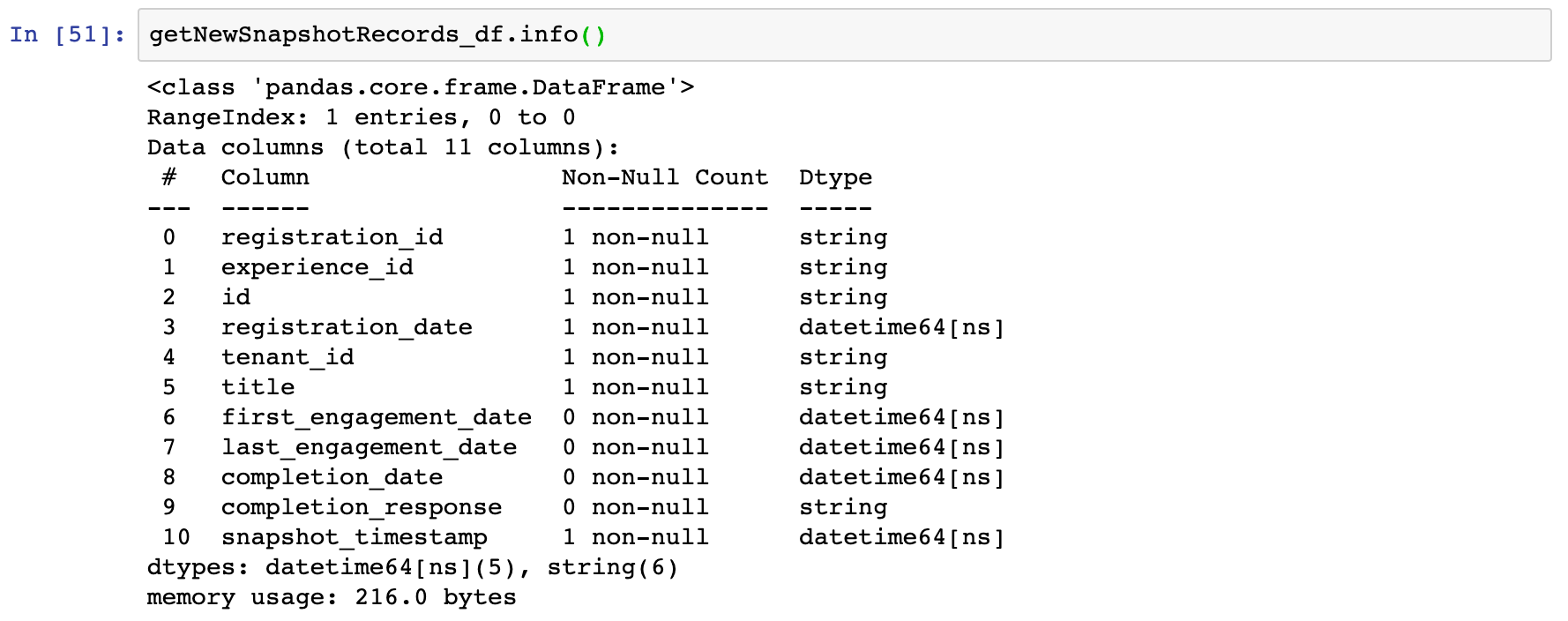
What I wanted to do now is convert these missing values (<NA>) into None as Spark is able to handle None values as null. To achieve this I converted the data types of the columns to object and then replaced any missing value to None.


Doing so, the AWS Glue job started failing with new error –
TypeError: field registration_date: TimestampType can not accept object Timestamp('2020-09-08 00:00:00') in type <class 'pandas._libs.tslibs.timestamps.Timestamp'>
If you closely notice at the df output in the screenshot above (block 53) displaying the record, the timestamp columns which were earlier showing NaT were replace with None. To resolve this, I converted back the columns containing timestamp to datetime data type.

Post these changes, the AWS Glue job has been running successfully and snapshot table has ~1K records being written to it in every execution of 15mins . So to summarize, I took below steps to handle the missing value in Pandas DataFrame and convert it into Spark DataFrame –
- After querying the data using AWS Data Wrangler Athena API, replaced missing values in the Pandas DataFrame with None.
- Converted the columns with timestamp data from object data type to datetime64 [ ns ] data type in Pandas DataFrame.
- Changed schema by creating the PySpark Schema using StructType and using it in
createDataFramemethod.

